1.两数之和
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出 和为目标值 target 的那 两个 整数,并返回它们的数组下标。
你可以假设每种输入只会对应一个答案,并且你不能使用两次相同的元素。
你可以按任意顺序返回答案。
示例 1:
- 输入:nums = [2,7,11,15], target = 9
- 输出:[0,1]
- 解释:因为 nums[0] + nums[1] == 9 ,返回 [0, 1] 。
解:
本题主要使用哈希思想,遍历nums数组,并查询target-nums[i]是否存在字典中,若不存在则将此数作为键,索引作为值加入字典中。
class Solution:
def twoSum(self, nums: List[int], target: int) -> List[int]:
pre=dict()
for index,num in enumerate(nums):
if target-num in pre:
return [pre[target-num],index]
pre[num]=index
return []2.字母异位词分组
给你一个字符串数组,请你将 字母异位词 组合在一起。可以按任意顺序返回结果列表。
示例 1:
输入: strs = ["eat", "tea", "tan", "ate", "nat", "bat"]
输出: [["bat"],["nat","tan"],["ate","eat","tea"]]
解释:
- 在 strs 中没有字符串可以通过重新排列来形成
"bat"。 - 字符串
"nat"和"tan"是字母异位词,因为它们可以重新排列以形成彼此。 - 字符串
"ate","eat"和"tea"是字母异位词,因为它们可以重新排列以形成彼此。
解:
将字符串内字母排序后作为键,原字符串作为值,再提取字典值即为需求的列表
class Solution:
def groupAnagrams(self, strs: List[str]) -> List[List[str]]:
d=defaultdict(list)
for s in strs:
sorted_s=''.join(sorted(s))
d[sorted_s].append(s)
return list(d.values())3.最长连续序列
给定一个未排序的整数数组 nums ,找出数字连续的最长序列(不要求序列元素在原数组中连续)的长度。
请你设计并实现时间复杂度为 O(n) 的算法解决此问题。
示例 1:
- 输入:nums = [100,4,200,1,3,2]
- 输出:4
- 解释:最长数字连续序列是 [1, 2, 3, 4]。它的长度为 4。
解:
首先对数组进行去重,因为连续序列中不会重复。遍历数组,通过查找nums[i]-1是否在数组中,忽视从序列中间开始的情况,只从序列头部开始。再在此基础上循环+1查找尾部终点。
class Solution:
def longestConsecutive(self, nums: List[int]) -> int:
st=set(nums)
ans=0
for i in st:
if i-1 in st:
continue
y=i+1
while y in st:
y+=1
ans=max(ans,y-i)
return ans
4.移动零
给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
请注意 ,必须在不复制数组的情况下原地对数组进行操作。
示例 1:
- 输入: nums =
[0,1,0,3,12] - 输出:
[1,3,12,0,0]
解:
双指针,一个指针指向0后第一个非0数,一个指针指向第一个0,通过交换将0后移
class Solution:
def moveZeroes(self, nums: List[int]) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
first_0=0
first_num=0
l_nums=len(nums)
while first_num<l_nums:
if nums[first_num] != 0:
nums[first_0],nums[first_num]=nums[first_num],nums[first_0]
first_0 +=1
first_num +=15.三数之和
给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i != j、i != k 且 j != k ,同时还满足 nums[i] + nums[j] + nums[k] == 0 。请你返回所有和为 0 且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例 1:
- 输入:nums = [-1,0,1,2,-1,-4]
- 输出:[[-1,-1,2],[-1,0,1]]
解释:
nums[0] + nums[1] + nums[2] = (-1) + 0 + 1 = 0 。
nums[1] + nums[2] + nums[4] = 0 + 1 + (-1) = 0 。
nums[0] + nums[3] + nums[4] = (-1) + 2 + (-1) = 0 。
不同的三元组是 [-1,0,1] 和 [-1,-1,2] 。
注意,输出的顺序和三元组的顺序并不重要。
解:
1.将数组排序
2.定1变2,遍历数组,并确定第一个数,在此数之后的区间内使用双指针定左右边界为起始位,两指针根据三数值与目标值的差距相向移动
3.添加一些过滤条件,减少遍历
class Solution:
def threeSum(self, nums: List[int]) -> List[List[int]]:
nums_sort=sorted(nums)
res=[]
for i in range(len(nums)):
if nums_sort[i]>0:
return res
if i>0 and nums_sort[i]==nums_sort[i-1]:
continue
left = i+1
right= len(nums)-1
while left<right:
sum_=nums_sort[i]+nums_sort[left]+nums_sort[right]
if sum_>0:
right-=1
elif sum_<0:
left+=1
else :
res.append([nums_sort[i],nums_sort[left],nums_sort[right]])
while right > left and nums_sort[right] == nums_sort[right - 1]:
right -= 1
while right > left and nums_sort[left] == nums_sort[left + 1]:
left += 1
right-=1
left+=1
return res6.盛最多水的容器
给定一个长度为 n 的整数数组 height 。有 n 条垂线,第 i 条线的两个端点是 (i, 0) 和 (i, height[i]) 。
找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
返回容器可以储存的最大水量。
说明:你不能倾斜容器。
示例 1:

- 输入:[1,8,6,2,5,4,8,3,7]
- 输出:49
- 解释:图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
解:
双指针从两侧出发,向中间逼近,移动一次计算一次面积,记录最大值
class Solution:
def maxArea(self, height: List[int]) -> int:
l=len(height)
left=0
right=l-1
x=l-1
v=min(height[left],height[right])*x
while left<right:
if height[left]<height[right]:
left+=1
x-=1
else :
right-=1
x-=1
v=max(v,min(height[left],height[right])*x)
return v7.接雨水
给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

- 输入:height = [0,1,0,2,1,0,1,3,2,1,2,1]
- 输出:6
- 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
解:
将横轴上每单位间隔看作一个独立容器,每个容器有个左边界、有边界与底,将所有容器容量和加起来即为结果。因此,先进行两次遍历,正序遍历得到前序最大值pre_max数组(左边界),后序遍历得到后续最大值数组suf_max数组(右边界),height数组即为底。
因此,单个容器的容量求解可表示为 min(左边界,右边界)-底 ,根据此遍历height完成计算求和即可
class Solution:
def trap(self, height: List[int]) -> int:
n=len(height)
pre_max=[0]*n
suf_max=[0]*n
res=0
pre_max[0]=height[0]
suf_max[-1]=height[-1]
for i in range(1,n):
pre_max[i]=max(pre_max[i-1],height[i])
for i in range(n-2,-1,-1):
suf_max[i]=max(suf_max[i+1],height[i])
for i in range(n):
res +=min(pre_max[i],suf_max[i])-height[i]
return res8.无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长 子串 的长度。
示例 1:
- 输入: s = "abcabcbb"
- 输出: 3
- 解释: 因为无重复字符的最长子串是
"abc",所以其长度为 3。注意 "bca" 和 "cab" 也是正确答案。
解:
双指针,left指向字串左侧,right指向字串右侧,并对字串字符进行计数,维持字串内各字符计数值不大于1,并记录合规子串的最大长度
class Solution:
def lengthOfLongestSubstring(self, s: str) -> int:
cnt=defaultdict(int)
left=ans=0
for right,c in enumerate(s):
cnt[c] +=1
while cnt[c]>1:
cnt[s[left]] -=1
left +=1
ans=max(ans,right-left+1)
return ans9.找到字符串中所有字母异位词
给定两个字符串 s 和 p,找到 s 中所有 p 的 异位词 的子串,返回这些子串的起始索引。不考虑答案输出的顺序。
示例 1:
- 输入: s = "cbaebabacd", p = "abc"
- 输出: [0,6]
- 解释:
- 起始索引等于 0 的子串是 "cba", 它是 "abc" 的异位词。
- 起始索引等于 6 的子串是 "bac", 它是 "abc" 的异位词。
解:
滑动窗口加计数匹配,定义字典cnt记录p中各字符的计数,在移动窗口时维护窗口内字符计数值,若值为0则删除元素,避免0与空值无法匹配
class Solution:
def findAnagrams(self, s: str, p: str) -> List[int]:
w_l=len(p)
cnt=defaultdict(int)
for c in p:
cnt[c] +=1
temp=defaultdict(int)
ans=[]
for right, c in enumerate(s):
temp[c] += 1 # 右端点字母进入窗口
left = right - w_l + 1
if left < 0: # 窗口长度不足 len(p)
continue
if cnt == temp: # t 和 p 的每种字母的出现次数都相同
ans.append(left) # t 左端点下标加入答案
temp[s[left]] -= 1 # 左端点字母离开窗口
if temp[s[left]]==0:
del temp[s[left]]
return ans10.和为 K 的子数组
给你一个整数数组 nums 和一个整数 k ,请你统计并返回 该数组中和为 k 的子数组的个数 。
子数组是数组中元素的连续非空序列。
示例 1:
- 输入:nums = [1,1,1], k = 2
- 输出:2
解:
计算前序和,子数组和为k,即s[i]-s[j]=k,s为前序和数组,i必须大于j
遍历前序和数组s,因为i必须大于j,将当前遍历到的数视为i,则j在前置数中挑选
在此使用cnt字典记录不同前置和出现的个数(只需要统计个数,不需要位置,因此无需记录index,只记录值),ans每次加上cnt[s[i]-k]即cnt[s[j]],即加上当前所有s[i]-s[j]=k可能情况
class Solution:
def subarraySum(self, nums: List[int], k: int) -> int:
s = [0]*(len(nums) + 1)
for i,num in enumerate(nums):
s[i+1] = s[i] + num
cnt = defaultdict(int)
ans = 0
for sj in s:
ans +=cnt[sj-k]
cnt[sj] += 1
return ans11.滑动窗口最大值
给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
返回 滑动窗口中的最大值 。
示例 1:
- 输入:nums = [1,3,-1,-3,5,3,6,7], k = 3
- 输出:[3,3,5,5,6,7]
解释:
滑动窗口的位置 最大值
--------------- -----
[1 3 -1] -3 5 3 6 7 3
1 [3 -1 -3] 5 3 6 7 3
1 3 [-1 -3 5] 3 6 7 5
1 3 -1 [-3 5 3] 6 7 5
1 3 -1 -3 [5 3 6] 7 6
1 3 -1 -3 5 [3 6 7] 7
解:
使用双端队列维护最大值,队首为最大值,第二个为队首元素后出现的最大值,当队首元素移出窗口后,第二个值作为当前最大值
具体流程为
1.从起始点开始构建滑动窗口,构建初始双端队列
2.队列维护流程:当新元素进入时,若队列不为空,将队列中所有小于新元素的值移除,再将新元素加入,这样可以维持当前一个最大值移除后,其后的值为当前窗口内的最大值
3.移动滑动窗口,判断左侧移出窗口的值是否为队首元素,若是则队列左侧元素出队。滑动窗口右侧一个新元素进队,同样的,若队列不为空,将队列中所有小于新元素的值移除,再将新元素加入
class Solution:
def maxSlidingWindow(self, nums: List[int], k: int) -> List[int]:
l=len(nums)
deque = collections.deque()
ans = []
for i in range(k):
while deque and deque[-1]<nums[i]:
deque.pop()
deque.append(nums[i])
ans.append(deque[0])
for i in range(k,l):
if deque[0]==nums[i-k]:
deque.popleft()
while deque and deque[-1]<nums[i]:
deque.pop()
deque.append(nums[i])
ans.append(deque[0])
return ans12.最小覆盖子串
给定两个字符串 s 和 t,长度分别是 m 和 n,返回 s 中的 最短窗口 子串,使得该子串包含 t 中的每一个字符(包括重复字符)。如果没有这样的子串,返回空字符串 ""。
测试用例保证答案唯一。
示例 1:
- 输入:s = "ADOBECODEBANC", t = "ABC"
- 输出:"BANC"
- 解释:最小覆盖子串 "BANC" 包含来自字符串 t 的 'A'、'B' 和 'C'。
解:
计数字串t字符数,定窗口左起点扩张右边界计数,直至窗口内计数结果包含t字符串计数整体,再在维持窗口内计数结果包含t字符串计数整体情况下移动左边界,直至无法包含
class Solution:
def minWindow(self, s: str, t: str) -> str:
cnt_s = Counter()
cnt_t = Counter(t)
ans_left,ans_right=-1,len(s)
left=0
for right,c in enumerate(s):
cnt_s[c] +=1
while cnt_s>=cnt_t:
if right-left<ans_right-ans_left:
ans_left,ans_right=left,right
cnt_s[s[left]] -=1
left +=1
return "" if ans_left<0 else s[ans_left:ans_right+1]13.最大子数组和
给你一个整数数组 nums ,请你找出一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
子数组是数组中的一个连续部分。
示例 1:
- 输入:nums = [-2,1,-3,4,-1,2,1,-5,4]
- 输出:6
- 解释:连续子数组 [4,-1,2,1] 的和最大,为 6 。
解:
两个思路
思路1:遍历过程中计算前缀和,并记录前缀和的最小值,当前前缀和-前缀和的最小值得到的最大值即为最大子数组和
思路2:维护前置最大子数组和,取max(pre_max,0)
思路1:
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
ans = -inf
min_pre_sum = pre_sum = 0
for x in nums:
pre_sum += x # 当前的前缀和
ans = max(ans, pre_sum - min_pre_sum) # 减去前缀和的最小值
min_pre_sum = min(min_pre_sum, pre_sum) # 维护前缀和的最小值
return ans思路2:
class Solution:
def maxSubArray(self, nums: List[int]) -> int:
ans=-inf
pre_max=0
for x in nums:
pre_max =max(pre_max,0)+x
ans=max(ans,pre_max)
return ans14.合并区间
以数组 intervals 表示若干个区间的集合,其中单个区间为 intervals[i] = [starti, endi] 。请你合并所有重叠的区间,并返回 一个不重叠的区间数组,该数组需恰好覆盖输入中的所有区间 。
示例 1:
- 输入:intervals = [[1,3],[2,6],[8,10],[15,18]]
- 输出:[[1,6],[8,10],[15,18]]
- 解释:区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6].
解:
将数组内区间按左边界排序,遍历时则满足新的区间左边界一定更大,若左边界小于最新合并区间的右边界,则可以进行合并。
class Solution:
def merge(self, intervals: List[List[int]]) -> List[List[int]]:
intervals.sort(key=lambda p:p[0])
ans=[]
for p in intervals:
if ans and p[0]<=ans[-1][1]:
ans[-1][1]=max(ans[-1][1],p[1])
else:
ans.append(p)
return ans15. 轮转数组
给定一个整数数组 nums,将数组中的元素向右轮转 k 个位置,其中 k 是非负数。
示例 1:
- 输入: nums = [1,2,3,4,5,6,7], k = 3
- 输出:
[5,6,7,1,2,3,4] - 解释:
- 向右轮转 1 步:
[7,1,2,3,4,5,6] - 向右轮转 2 步:
[6,7,1,2,3,4,5] - 向右轮转 3 步:
[5,6,7,1,2,3,4]
解:
轮转k个位置,即后k个数被提前到了数组首位置,且反转两层为正序,因此先整体反转,再反转前k个数,再将后续数反转回正序,即实现了将后k个数被提前到了数组首位置
class Solution:
def rotate(self, nums: List[int], k: int) -> None:
"""
Do not return anything, modify nums in-place instead.
"""
def reverse(i:int,j:int)->None:
while i<j:
nums[i],nums[j]=nums[j],nums[i]
i+=1
j-=1
l=len(nums)
k=k%l
reverse(0,l-1)
reverse(0,k-1)
reverse(k,l-1)16. 除了自身以外数组的乘积
给你一个整数数组 nums,返回 数组 answer ,其中 answer[i] 等于 nums 中除了 nums[i] 之外其余各元素的乘积 。
题目数据 保证 数组 nums之中任意元素的全部前缀元素和后缀的乘积都在 32 位 整数范围内。
请 不要使用除法,且在 O(n) 时间复杂度内完成此题。
示例 1:
- 输入: nums =
[1,2,3,4] - 输出:
[24,12,8,6]
解:
计算前序乘积,后序乘积,除自身外的乘积为左侧前序乘积乘右侧后续乘积
class Solution:
def productExceptSelf(self, nums: List[int]) -> List[int]:
n=len(nums)
pre=[1]*n
suf=[1]*n
for i in range(1, n):
pre[i] = pre[i - 1] * nums[i - 1]
for i in range(n - 2, -1, -1):
suf[i] = suf[i + 1] * nums[i + 1]
res=[]
for p,s in zip(pre,suf):
res.append(p*s)
return res17. 缺失的第一个正数
给你一个未排序的整数数组 nums ,请你找出其中没有出现的最小的正整数。请你实现时间复杂度为 O(n) 并且只使用常数级别额外空间的解决方案。
示例 1:
- 输入:nums = [1,2,0]
- 输出:3
- 解释:范围 [1,2] 中的数字都在数组中。
解:
缺失的第一个正数,正数从1开始,可与数组index对应,按index=value重排,找到index!=value,即找到结果。若重排后数组中每个元素均满足条件,则最小正整数为len(nums)+1
class Solution:
def firstMissingPositive(self, nums: List[int]) -> int:
for i in range(len(nums)):
# 注意此处不能用if,否则会导致部分元素被跳过,没有被放置到正确位置
while 1 <= nums[i] <= len(nums) and nums[nums[i] - 1] != nums[i]:
# 那么就交换 nums[i] 和 nums[j],其中 j 是 i 的学号
j = nums[i] - 1 # 减一是因为数组下标从 0 开始
nums[i], nums[j] = nums[j], nums[i]
for i,n in enumerate(nums):
if n!=i+1:
return i+1
return len(nums)+118.矩阵置零
给定一个 m x n 的矩阵,如果一个元素为 0 ,则将其所在行和列的所有元素都设为 0 。请使用 原地 算法。
示例 1:
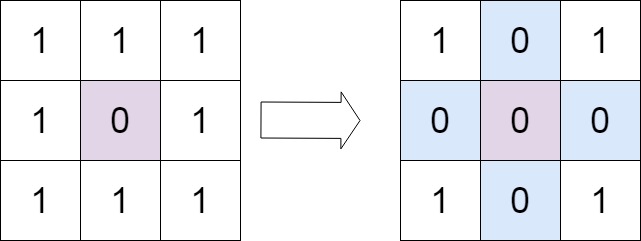
- 输入:matrix = [[1,1,1],[1,0,1],[1,1,1]]
- 输出:[[1,0,1],[0,0,0],[1,0,1]]
示例 2:
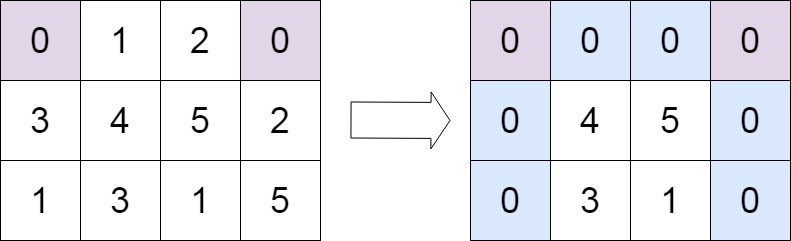
- 输入:matrix = [[0,1,2,0],[3,4,5,2],[1,3,1,5]]
- 输出:[[0,0,0,0],[0,4,5,0],[0,3,1,0]]
解:
使用两个set()分别记录下0点横坐标和纵坐标,再根据记录进行置零
class Solution:
def setZeroes(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
# 获取矩阵的行数和列数
row_count = len(matrix)
col_count = len(matrix[0]) if row_count > 0 else 0
# 用集合记录需要置零的行和列
zero_rows = set()
zero_cols = set()
# 第一步:遍历矩阵,标记所有0所在的行和列
for i in range(row_count):
for j in range(col_count):
if matrix[i][j] == 0:
zero_rows.add(i) # 记录0所在的行索引i
zero_cols.add(j) # 记录0所在的列索引j
# 第二步:将标记的行全部置零
for row_idx in zero_rows:
for col_idx in range(col_count):
matrix[row_idx][col_idx] = 0
# 第三步:将标记的列全部置零
for col_idx in zero_cols:
for row_idx in range(row_count):
matrix[row_idx][col_idx] = 019.螺旋矩阵
给你一个 m 行 n 列的矩阵 matrix ,请按照 顺时针螺旋顺序 ,返回矩阵中的所有元素。
示例 1:

- 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
- 输出:[1,2,3,6,9,8,7,4,5]
解:
模拟遍历过程实现
class Solution:
def spiralOrder(self, matrix: List[List[int]]) -> List[int]:
"""
螺旋顺序遍历二维矩阵,返回遍历结果列表
:param matrix: 待遍历的二维矩阵
:return: 按螺旋顺序排列的元素列表
"""
# 获取矩阵的行数
row_cnt = len(matrix)
# 获取矩阵的列数(处理空矩阵避免索引越界)
col_cnt = len(matrix[0]) if row_cnt > 0 else 0
# 存储最终的螺旋遍历结果
res = []
# 定义四个边界:左、右、上、下
left = 0 # 左边界(初始为第0列)
right = col_cnt - 1 # 右边界(初始为最后一列)
top = 0 # 上边界(初始为第0行)
bottom = row_cnt - 1 # 下边界(初始为最后一行)
# 循环条件:左边界不超过右边界,且上边界不超过下边界
while left <= right and top <= bottom:
# 第一步:从左到右遍历上边界所在的行(顶行)
for column in range(left, right + 1):
res.append(matrix[top][column])
# 第二步:从上到下遍历右边界所在的列(右列),注意跳过已遍历的顶行元素
for row in range(top + 1, bottom + 1):
res.append(matrix[row][right])
# 关键判断:只有当左<右且上<下时,才需要遍历下面和左面(避免单行/单列重复遍历)
if left < right and top < bottom:
# 第三步:从右到左遍历下边界所在的行(底行),注意跳过已遍历的右列元素
for column in range(right - 1, left, -1):
res.append(matrix[bottom][column])
# 第四步:从下到上遍历左边界所在的列(左列),注意跳过已遍历的底行和顶行元素
for row in range(bottom, top, -1):
res.append(matrix[row][left])
# 收缩边界:左边界右移、右边界左移、上边界下移、下边界上移,进入内层循环
left += 1
right -= 1
top += 1
bottom -= 1
# 返回螺旋遍历结果
return res20.旋转图像
给定一个 n × n 的二维矩阵 matrix 表示一个图像。请你将图像顺时针旋转 90 度。
你必须在 原地 旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要 使用另一个矩阵来旋转图像。
示例 1:
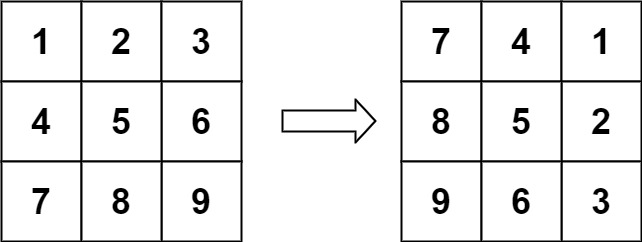
- 输入:matrix = [[1,2,3],[4,5,6],[7,8,9]]
- 输出:[[7,4,1],[8,5,2],[9,6,3]]
解:
沿主对角线翻转,在沿中轴翻转,即可得到顺时针旋转90度的图像
class Solution:
def rotate(self, matrix: List[List[int]]) -> None:
"""
Do not return anything, modify matrix in-place instead.
"""
n=len(matrix)
for i in range(n):
for j in range(i):
matrix[i][j],matrix[j][i]=matrix[j][i],matrix[i][j]
for row in matrix:
row.reverse()21.搜索二维矩阵 II
编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
- 每行的元素从左到右升序排列。
- 每列的元素从上到下升序排列。
示例 1:
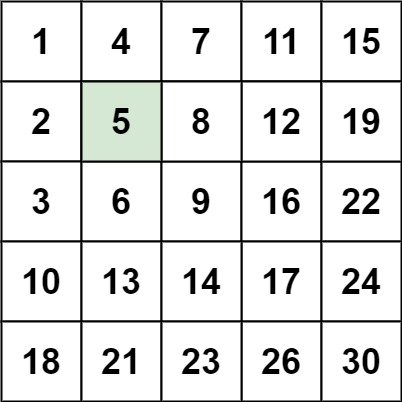
- 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5
- 输出:true
示例 2:
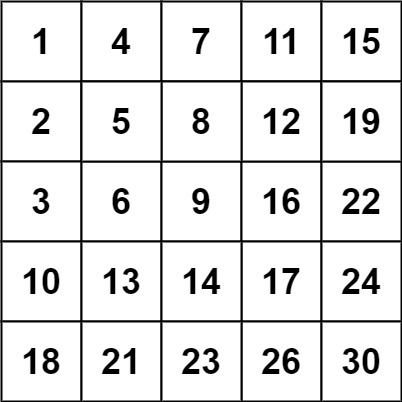
- 输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 20
- 输出:false
解:
每行的元素从左到右升序排列,每列的元素从上到下升序排列。因此可以根据每行左右极值判断target是否有在本行的可能,若有则查找,没有则跳过或根据情况返回False。查找时可采用二分查找
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
row = len(matrix)
col = len(matrix[0])
if target<matrix[0][0] or target>matrix[row-1][col-1]:
return False
p_row = 0
while p_row<row:
if target<matrix[p_row][0]:
return False
elif target>matrix[p_row][-1]:
p_row +=1
continue
else:
left,right=0,col-1
while left<=right:
mid=(left+right)//2
if target==matrix[p_row][mid]:
return True
elif target>matrix[p_row][mid]:
left=mid+1
else:
right=mid -1
p_row +=1
return False巧妙解法:(灵茶山艾府)
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
m, n = len(matrix), len(matrix[0])
i, j = 0, n - 1 # 从右上角开始
while i < m and j >= 0: # 还有剩余元素
if matrix[i][j] == target:
return True # 找到 target
if matrix[i][j] < target:
i += 1 # 这一行剩余元素全部小于 target,排除
else:
j -= 1 # 这一列剩余元素全部大于 target,排除
return False22.相交链表
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
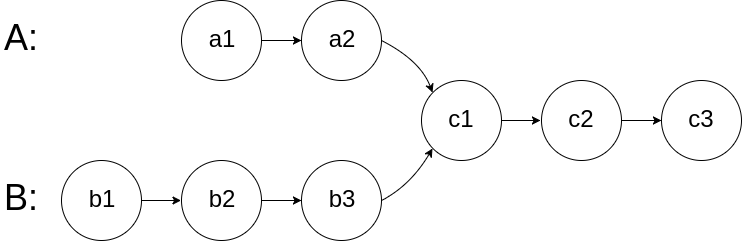
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:

输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
解:
从两个起点出发遍历两条链表,两条路线之和均为两条链表长度之和。若有相交,则会在交点相遇
class Solution:
def getIntersectionNode(self, headA: ListNode, headB: ListNode) -> Optional[ListNode]:
p1=headA
p2=headB
cnt=0
while cnt<2:
if p1==p2:
return p1
if p1.next:
p1=p1.next
else :
p1=headB
cnt+=1
if p2.next:
p2=p2.next
else:
p2=headA
return None23. 反转链表
给你单链表的头节点 head ,请你反转链表,并返回反转后的链表。
示例 1:
- 输入:head = [1,2,3,4,5]
- 输出:[5,4,3,2,1]
解:
原地反转即可
class Solution:
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
p=head
last=None
while p:
temp=p.next
p.next=last
last=p
p=temp
return last24.回文链表
给你一个单链表的头节点 head ,请你判断该链表是否为回文链表。如果是,返回 true ;否则,返回 false 。
示例 1:

- 输入:head = [1,2,2,1]
- 输出:true
解:
转换成数组再反转对比
class Solution:
def isPalindrome(self, head: Optional[ListNode]) -> bool:
temp=[]
p=head
while p:
temp.append(p.val)
p=p.next
if temp==temp[::-1]:
return True
else:
return False快慢指针找到链表中点,反转后半部分链表,从两头向中间趋近对比(灵茶山艾府)
class Solution:
# 876. 链表的中间结点
def middleNode(self, head: Optional[ListNode]) -> Optional[ListNode]:
slow = fast = head
while fast and fast.next:
slow = slow.next
fast = fast.next.next
return slow
# 206. 反转链表
def reverseList(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre, cur = None, head
while cur:
nxt = cur.next
cur.next = pre
pre = cur
cur = nxt
return pre
def isPalindrome(self, head: Optional[ListNode]) -> bool:
mid = self.middleNode(head)
head2 = self.reverseList(mid)
while head2:
if head.val != head2.val: # 不是回文链表
return False
head = head.next
head2 = head2.next
return True25.环形链表
给你一个链表的头节点 head ,判断链表中是否有环。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。注意:pos 不作为参数进行传递 。仅仅是为了标识链表的实际情况。
如果链表中存在环 ,则返回 true 。 否则,返回 false 。
示例 1:
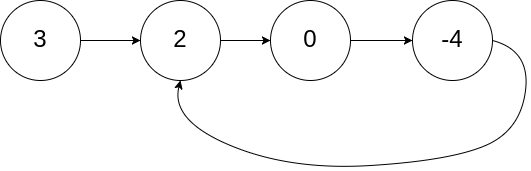
输入:head = [3,2,0,-4], pos = 1 输出:true 解释:链表中有一个环,其尾部连接到第二个节点。
解:
快慢指针,快指针追上慢指针则说明有环
class Solution:
def hasCycle(self, head: Optional[ListNode]) -> bool:
slow=head
fast=head
while fast and fast.next:
slow=slow.next
fast=fast.next.next
if fast==slow:
return True
return False26.环形链表 II
给定一个链表的头节点 head ,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
如果链表中有某个节点,可以通过连续跟踪 next 指针再次到达,则链表中存在环。 为了表示给定链表中的环,评测系统内部使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。如果 pos 是 -1,则在该链表中没有环。注意:pos 不作为参数进行传递,仅仅是为了标识链表的实际情况。
不允许修改 链表。
示例 1:

输入:head = [3,2,0,-4], pos = 1 输出:返回索引为 1 的链表节点 解释:链表中有一个环,其尾部连接到第二个节点。
解:

class Solution:
def detectCycle(self, head: Optional[ListNode]) -> Optional[ListNode]:
slow=head
fast=head
while fast and fast.next:
slow=slow.next
fast=fast.next.next
if slow==fast:
temp=head
while temp!=slow:
temp=temp.next
slow=slow.next
return slow
return None27.合并两个有序链表
将两个升序链表合并为一个新的 升序 链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例 1:

输入:l1 = [1,2,4], l2 = [1,3,4] 输出:[1,1,2,3,4,4]
解:
依次遍历比大小插入
class Solution:
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
l1=list1
l2=list2
cur=head=ListNode()
while l1 and l2:
if l1.val<l2.val:
cur.next=l1
l1=l1.next
cur=cur.next
else :
cur.next=l2
l2=l2.next
cur=cur.next
cur.next=l1 or l2
return head.next28.两数相加
给你两个 非空 的链表,表示两个非负的整数。它们每位数字都是按照 逆序 的方式存储的,并且每个节点只能存储 一位 数字。
请你将两个数相加,并以相同形式返回一个表示和的链表。
你可以假设除了数字 0 之外,这两个数都不会以 0 开头。
示例 1:
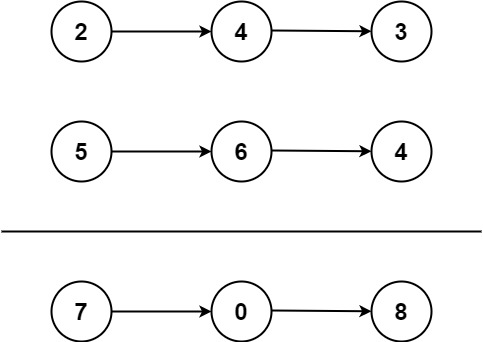
输入:l1 = [2,4,3], l2 = [5,6,4] 输出:[7,0,8] 解释:342 + 465 = 807.
解:
数值可能越界,因此不能整个数读出来加再拆解。在此逐位加并计算进位,%10求余赋值,//10进位
class Solution:
def addTwoNumbers(self, l1: Optional[ListNode], l2: Optional[ListNode]) -> Optional[ListNode]:
carry=0
head=cur=ListNode()
while l1 or l2 or carry:
if l1:
carry += l1.val # 节点值和进位加在一起
l1 = l1.next # 下一个节点
if l2:
carry += l2.val # 节点值和进位加在一起
l2 = l2.next # 下一个节点
cur.next = ListNode(carry % 10) # 每个节点保存一个数位
carry //= 10 # 新的进位
cur = cur.next # 下一个节点
return head.next29.删除链表的倒数第 N 个结点
给你一个链表,删除链表的倒数第 n 个结点,并且返回链表的头结点。
示例 1:

- 输入:head = [1,2,3,4,5], n = 2
- 输出:[1,2,3,5]
解:
链表总长为L,定左右指针,右指针先走n,左右指针再同步走剩余的L-n,则左指针指向的便是倒数第n个节点,为避免头节点被删除,定义dummy指针,dummy.next指向head
class Solution:
def removeNthFromEnd(self, head: Optional[ListNode], n: int) -> Optional[ListNode]:
left=right=dummy=ListNode(next=head)
for i in range(n):
right=right.next
while right.next:
left=left.next
right=right.next
left.next=left.next.next
return dummy.next30.两两交换链表中的节点
给你一个链表,两两交换其中相邻的节点,并返回交换后链表的头节点。你必须在不修改节点内部的值的情况下完成本题(即,只能进行节点交换)。
示例 1:

- 输入:head = [1,2,3,4]
- 输出:[2,1,4,3]
解:
定义dummy固定链表头,pre为交换前一个节点,left为交换左节点,right为交换右节点,左右节点均不为空进行节点交换
class Solution:
def swapPairs(self, head: Optional[ListNode]) -> Optional[ListNode]:
pre=dummy=left=right=ListNode(next=head)
if head==None or head.next==None:
return head
left=pre.next
right=pre.next.next
while left and right:
pre.next=right
left.next=right.next
right.next=left
pre=left
left=left.next
right=left.next if left else None
return dummy.next31.K 个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。
示例 1:

- 输入:head = [1,2,3,4,5], k = 2
- 输出:[2,1,4,3,5]
解:
1.遍历链表,看看需要反转多少组(n/k)
2.局部反转后还需要链接,因此需要留下链接锚点,定义链接锚点p0,p0.next为未反转的局部链表起点
3.反转局部链表,完成一组反转后通过链接锚点重新链接,并将锚点跳转至下一组
class Solution:
def reverseKGroup(self, head: Optional[ListNode], k: int) -> Optional[ListNode]:
n=0
cur=head
while cur:
n+=1
cur=cur.next
p0=dummy=ListNode(next=head)
pre=None
cur=head
while n>=k:
n-=k
#反转局部链表
for i in range(k):
nxt=cur.next
cur.next=pre
pre=cur
cur=nxt
#跳转锚点
nxt=p0.next
nxt.next=cur
p0.next=pre
p0=nxt
return dummy.next32.随机链表的复制
给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点。
构造这个链表的 深拷贝。 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值。新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态。复制链表中的指针都不应指向原链表中的节点 。
例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y 。那么在复制链表中对应的两个节点 x 和 y ,同样有 x.random --> y 。
返回复制链表的头节点。
用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
val:一个表示Node.val的整数。random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
你的代码 只 接受原链表的头节点 head 作为传入参数。
示例 1:
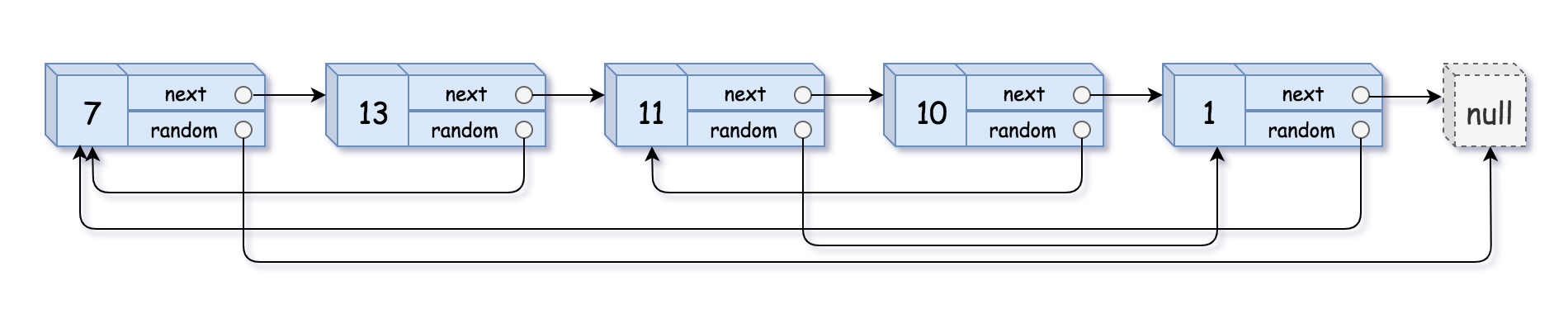
- 输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]]
- 输出:[[7,null],[13,0],[11,4],[10,2],[1,0]]
解:
解法1:哈希存储
import collections
class Solution:
def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':
L_dict=collections.defaultdict()
if head==None:
return None
L=head
while L:
L_dict[L]=Node(L.val)
L=L.next
L=head
while L:
L_dict[L].next=L_dict.get(L.next)
L_dict[L].random=L_dict.get(L.random)
L=L.next
return L_dict[head]解法2:我们可以把新链表和旧链表「混在一起」。
例如链表 1→2→3,依次复制每个节点(创建新节点并复制 val 和 next),把新节点直接插到原节点的后面,形成一个交错链表:
1→1′→2→2′→3→3′
如此一来,原链表节点的下一个节点,就是其对应的新链表节点了
class Solution:
def copyRandomList(self, head: 'Optional[Node]') -> 'Optional[Node]':
# 复制每个节点,把新节点直接插到原节点的后面
cur = head
while cur:
cur.next = Node(cur.val, cur.next)
cur = cur.next.next
# 遍历交错链表中的原链表节点
cur = head
while cur:
if cur.random:
# 要复制的 random 是 cur.random 的下一个节点
cur.next.random = cur.random.next
cur = cur.next.next
# 把交错链表分离成两个链表
tail = dummy = Node(0, head)
cur = head
while cur:
copy = cur.next # 新节点
tail.next = copy # 把新节点插在 tail 的后面,构建新的链表
cur.next = copy.next # 恢复原节点的 next
cur = cur.next
tail = tail.next
return dummy.next33.排序链表
给你链表的头结点 head ,请将其按 升序 排列并返回 排序后的链表 。
示例 1:

- 输入:head = [4,2,1,3]
- 输出:[1,2,3,4]
解:
分治排序在链表中应用
class Solution:
def middleNode(self,head:Optional[ListNode]) -> Optional[ListNode]:
slow=head
fast=head
while fast and fast.next:
pre=slow
slow=slow.next
fast=fast.next.next
pre.next=None
return slow
def mergeTwoLists(self,list1:Optional[ListNode],list2:Optional[ListNode]):
cur=dummy=ListNode()
while list1 and list2:
if list1.val<list2.val:
cur.next=list1
cur=cur.next
list1=list1.next
else:
cur.next=list2
cur=cur.next
list2=list2.next
cur.next=list1 if list1 else list2
return dummy.next
def sortList(self, head: Optional[ListNode]) -> Optional[ListNode]:
if head==None or head.next==None:
return head
head2=self.middleNode(head)
head=self.sortList(head)
head2=self.sortList(head2)
return self.mergeTwoLists(head,head2)34.合并 K 个升序链表
给你一个链表数组,每个链表都已经按升序排列。
请你将所有链表合并到一个升序链表中,返回合并后的链表。
示例 1:
- 输入:lists = [[1,4,5],[1,3,4],[2,6]]
- 输出:[1,1,2,3,4,4,5,6]
- 解释:链表数组如下:
- [
- 1->4->5,
- 1->3->4,
- 2->6
- ]
- 将它们合并到一个有序链表中得到。
- 1->1->2->3->4->4->5->6
解:
分治递归
class Solution:
# 合并两个有序链表
def mergeTwoLists(self, list1: Optional[ListNode], list2: Optional[ListNode]) -> Optional[ListNode]:
cur = dummy = ListNode() # 用哨兵节点简化代码逻辑
while list1 and list2:
if list1.val < list2.val:
cur.next = list1 # 把 list1 加到新链表中
list1 = list1.next
else: # 注:相等的情况加哪个节点都是可以的
cur.next = list2 # 把 list2 加到新链表中
list2 = list2.next
cur = cur.next
cur.next = list1 if list1 else list2 # 拼接剩余链表
return dummy.next
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
m = len(lists)
if m == 0:
return None
if m == 1:
return lists[0] # 无需合并,直接返回
left = self.mergeKLists(lists[:m // 2]) # 合并左半部分
right = self.mergeKLists(lists[m // 2:]) # 合并右半部分
return self.mergeTwoLists(left, right) # 最后把左半和右半合并分治迭代
class Solution:
def megeTwoList(self, list1: Optional[ListNode],list2: Optional[ListNode])->Optional[ListNode]:
cur=dummy=ListNode()
while list1 and list2:
if list1.val<list2.val:
cur.next=list1
cur=cur.next
list1=list1.next
else:
cur.next=list2
cur=cur.next
list2=list2.next
cur.next=list1 if list1 else list2
return dummy.next
def mergeKLists(self, lists: List[Optional[ListNode]]) -> Optional[ListNode]:
n=len(lists)
if n==0:
return None
step=1
while step<n:
for i in range(0,n-step,step*2):
lists[i]=self.megeTwoList(lists[i],lists[i+step])
step*=2
return lists[0]35.LRU 缓存
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
LRUCache(int capacity)以 正整数 作为容量capacity初始化 LRU 缓存int get(int key)如果关键字key存在于缓存中,则返回关键字的值,否则返回-1。void put(int key, int value)如果关键字key已经存在,则变更其数据值value;如果不存在,则向缓存中插入该组key-value。如果插入操作导致关键字数量超过capacity,则应该 逐出 最久未使用的关键字。
函数 get 和 put 必须以 O(1) 的平均时间复杂度运行。
示例:
- 输入
- ["LRUCache", "put", "put", "get", "put", "get", "put", "get", "get", "get"]
- [[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
- 输出
- [null, null, null, 1, null, -1, null, -1, 3, 4]
解释 LRUCache lRUCache = new LRUCache(2); lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3}
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3}
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
解:
使用双向链表构建数据结构,dummy同时作为链表头和尾,构建哈希表存储key:Node的映射
读取值时将先用哈希表判定值是否存在,存在则将节点取出并放置到链表头dummy之后,不存在则返回-1
放置值时先用哈希表判定值是否存在,存在则将node.val覆盖新值,并前置节点,不存在则创建新节点置于链表头dummy之后。哈希表key_to_node同步更新。若存量缓存数大于capacity,则删除dummy的prev节点(链表尾节点)。
class Node:
def __init__(self,key=0,val=0):
self.val=val
self.key=key
self.prev=None
self.next=None
class LRUCache:
def out_node(self,node:Node)-> None:
node.prev.next=node.next
node.next.prev=node.prev
def in_node(self,node:Node)-> None:
node.prev=self.dummy
node.next=self.dummy.next
self.dummy.next.prev=node
self.dummy.next=node
def __init__(self, capacity: int):
self.capacity=capacity
self.dummy=Node()
self.dummy.prev=self.dummy
self.dummy.next=self.dummy
self.key_to_node={}
def get(self, key: int) -> int:
if key in self.key_to_node:
node = self.key_to_node[key]
self.out_node(node)
self.in_node(node)
return node.val
else:
return -1
def put(self, key: int, value: int) -> None:
if key in self.key_to_node:
node = self.key_to_node[key]
node.val=value
self.out_node(node)
self.in_node(node)
else:
node=Node(key,value)
self.in_node(node)
self.key_to_node[key]=node
if len(self.key_to_node)>self.capacity:
node=self.dummy.prev
self.out_node(node)
del self.key_to_node[node.key]36.二叉树的中序遍历
给定一个二叉树的根节点 root ,返回 它的 中序 遍历 。
示例 1:

- 输入:root = [1,null,2,3]
- 输出:[1,3,2]
解:
前序遍历:根-左-右,先获取根节点值,再访问根的左子树,最后访问根的右子树
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
def dfs(node:Optional[TreeNode])->None:
if node is None:
return
ans.append(node.val)
dfs(node.left)
dfs(node.right)
ans=[]
dfs(root)
return ans中序遍历:左-根-右。先访问根的左子树,再获取根节点值,最后访问根的右子树
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
def dfs(node:Optional[TreeNode])->None:
if node is None:
return
dfs(node.left)
ans.append(node.val)
dfs(node.right)
ans=[]
dfs(root)
return ans后序遍历:左-右-根。先访问根的左子树,再访问根的右子树,最后获取根节点值
class Solution:
def inorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
def dfs(node:Optional[TreeNode])->None:
if node is None:
return
dfs(node.left)
dfs(node.right)
ans.append(node.val)
ans=[]
dfs(root)
return ans37.二叉树的最大深度
给定一个二叉树 root ,返回其最大深度。
二叉树的 最大深度 是指从根节点到最远叶子节点的最长路径上的节点数。
示例 1:
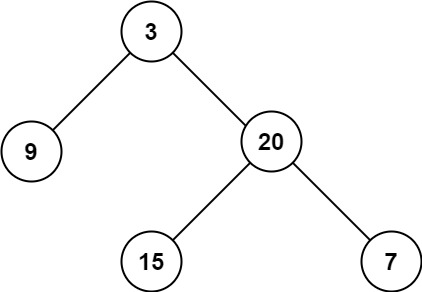
- 输入:root = [3,9,20,null,null,15,7]
- 输出:3
解:
方法一:自底向上
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
if root is None:
return 0
l_depth = self.maxDepth(root.left)
r_depth = self.maxDepth(root.right)
return max(l_depth, r_depth) + 1方法二:自顶向下
class Solution:
def maxDepth(self, root: Optional[TreeNode]) -> int:
ans=0
def dfs(node: Optional[TreeNode],level:int) -> int:
if not node:
return
level+=1
nonlocal ans
ans=max(ans,level)
dfs(node.left,level)
dfs(node.right,level)
dfs(root,0)
return ans38.翻转二叉树
给你一棵二叉树的根节点 root ,翻转这棵二叉树,并返回其根节点。
示例 1:
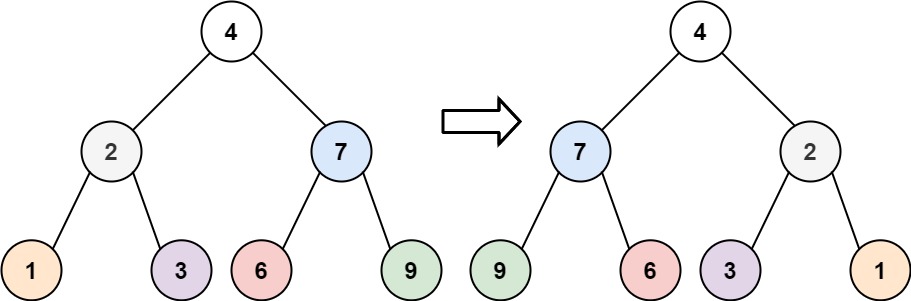
- 输入:root = [4,2,7,1,3,6,9]
- 输出:[4,7,2,9,6,3,1]
解:
递归写法,递归翻转左子树,递归翻转右子树,交换左右子树
class Solution:
def invertTree(self, root: Optional[TreeNode]) -> Optional[TreeNode]:
if root==None:
return None
left=self.invertTree(root.left)
right=self.invertTree(root.right)
root.left=right
root.right=left
return root39.对称二叉树
给你一个二叉树的根节点 root , 检查它是否轴对称。
示例 1:
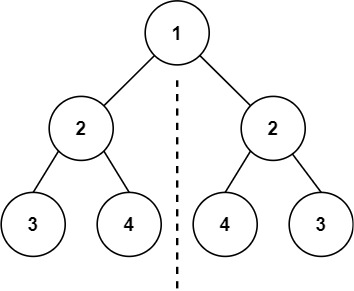
- 输入:root = [1,2,2,3,4,4,3]
- 输出:true
解:
把输入的二叉树拆分成左子树 p 和右子树 q。我们需要判断 p 和 q 是否互为镜像。
class Solution:
def isSameTree(self,p:Optional[TreeNode],q:Optional[TreeNode])->bool:
if p==None or q==None:
return p is q
return p.val==q.val and self.isSameTree(p.left,q.right) and self.isSameTree(p.right,q.left)
def isSymmetric(self, root: Optional[TreeNode]) -> bool:
ans=self.isSameTree(root.left,root.right)
return ans40.二叉树的直径
给你一棵二叉树的根节点,返回该树的 直径 。
二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。
两节点之间路径的 长度 由它们之间边数表示。
示例 1:
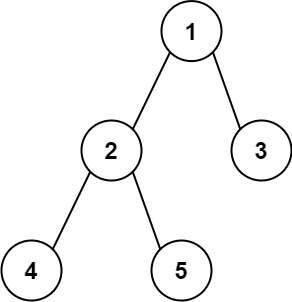
- 输入:root = [1,2,3,4,5]
- 输出:3
- 解释:3 ,取路径 [4,2,1,3] 或 [5,2,1,3] 的长度。
解:
递归,在每一个节点拆分处计算一次极值
class Solution:
def diameterOfBinaryTree(self, root: Optional[TreeNode]) -> int:
ans=0
def dfs(node:Optional[TreeNode])->int:
if node==None:
return -1
l_len=dfs(node.left)+1
r_len=dfs(node.right)+1
nonlocal ans
ans=max(ans,l_len+r_len)
return max(l_len,r_len)
dfs(root)
return ans41.二叉树的层序遍历
给你二叉树的根节点 root ,返回其节点值的 层序遍历 。 (即逐层地,从左到右访问所有节点)。
示例 1:

- 输入:root = [3,9,20,null,null,15,7]
- 输出:[[3],[9,20],[15,7]]
解:
构造一个队列存储每行节点,遍历每行前先计算当前行有多少节点需要遍历,遍历节点时将下一行节点从左到右加入队列,遍历过的节点出队列,直至队列为空
class Solution:
def levelOrder(self, root: Optional[TreeNode]) -> List[List[int]]:
if root==None:
return []
ans=[]
temp=deque([root])
while temp:
vals=[]
for i in range(len(temp)):
node=temp.popleft()
vals.append(node.val)
if node.left:
temp.append(node.left)
if node.right:
temp.append(node.right)
ans.append(vals)
return ans42.将有序数组转换为二叉搜索树
给你一个整数数组 nums ,其中元素已经按 升序 排列,请你将其转换为一棵 平衡 二叉搜索树。
示例 1:
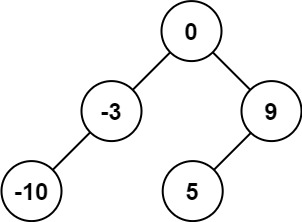
- 输入:nums = [-10,-3,0,5,9]
- 输出:[0,-3,9,-10,null,5]
- 解释:[0,-10,5,null,-3,null,9] 也将被视为正确答案:
解:
递归,每次将数组拆分为三部分,左部分,中间数,右部分,每次将中间数构造节点,并为其指向左节点和右节点(递归返回)
class Solution:
def sortedArrayToBST(self, nums: List[int]) -> Optional[TreeNode]:
if not nums:
return None
m=len(nums)//2
left=self.sortedArrayToBST(nums[:m])
right=self.sortedArrayToBST(nums[m+1:])
return TreeNode(nums[m],left,right)43.验证二叉搜索树
给你一个二叉树的根节点 root ,判断其是否是一个有效的二叉搜索树。
有效 二叉搜索树定义如下:
- 节点的左子树只包含 严格小于 当前节点的数。
- 节点的右子树只包含 严格大于 当前节点的数。
- 所有左子树和右子树自身必须也是二叉搜索树。
示例 1:

- 输入:root = [2,1,3]
- 输出:true
解
中序遍历递归,左中右,结合二叉搜索树特性,可知新节点应大于所有前置节点
class Solution:
pre=-inf
def isValidBST(self, root: Optional[TreeNode]) -> bool:
if root is None:
return True
if not self.isValidBST(root.left):
return False
if root.val<=self.pre:
return False
self.pre=root.val
return self.isValidBST(root.right)44.二叉搜索树中第 K 小的元素
给定一个二叉搜索树的根节点 root ,和一个整数 k ,请你设计一个算法查找其中第 k 小的元素(k 从 1 开始计数)。
示例 1:
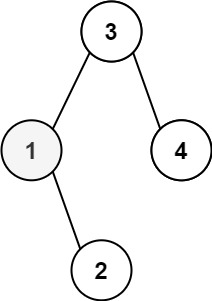
- 输入:root = [3,1,4,null,2], k = 1
- 输出:1
解:
二叉搜索树特性,中序遍历结果为从小到大,中序递归计数并记录结果
class Solution:
def kthSmallest(self, root: Optional[TreeNode], k: int) -> int:
ans=0
def dfs(node: Optional[TreeNode])->None:
nonlocal k,ans
if not node or k<=0:
return
dfs(node.left)
k -=1
if k==0:
ans=node.val
dfs(node.right)
dfs(root)
return ans45.二叉树的右视图
给定一个二叉树的 根节点 root,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
示例 1:
输入:root = [1,2,3,null,5,null,4]
输出:[1,3,4]
解释:
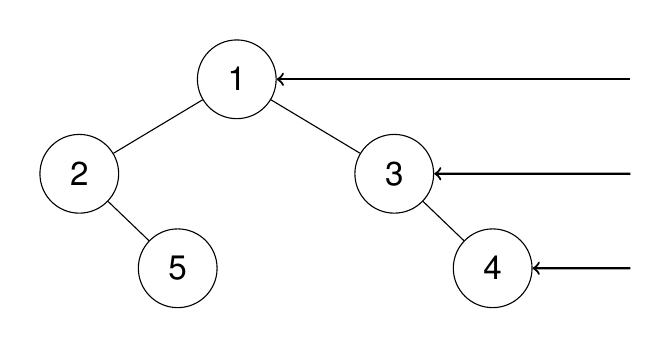
解:
层序遍历,取每层最右侧记录
class Solution:
def rightSideView(self, root: Optional[TreeNode]) -> List[int]:
q=deque([root])
ans=[]
if not root:
return ans
while q:
n=len(q)
ans.append(q[n-1].val)
for i in range(n):
node=q.popleft()
if node.left:
q.append(node.left)
if node.right:
q.append(node.right)
return ans46.二叉树展开为链表
给你二叉树的根结点 root ,请你将它展开为一个单链表:
- 展开后的单链表应该同样使用
TreeNode,其中right子指针指向链表中下一个结点,而左子指针始终为null。 - 展开后的单链表应该与二叉树 先序遍历 顺序相同。
示例 1:
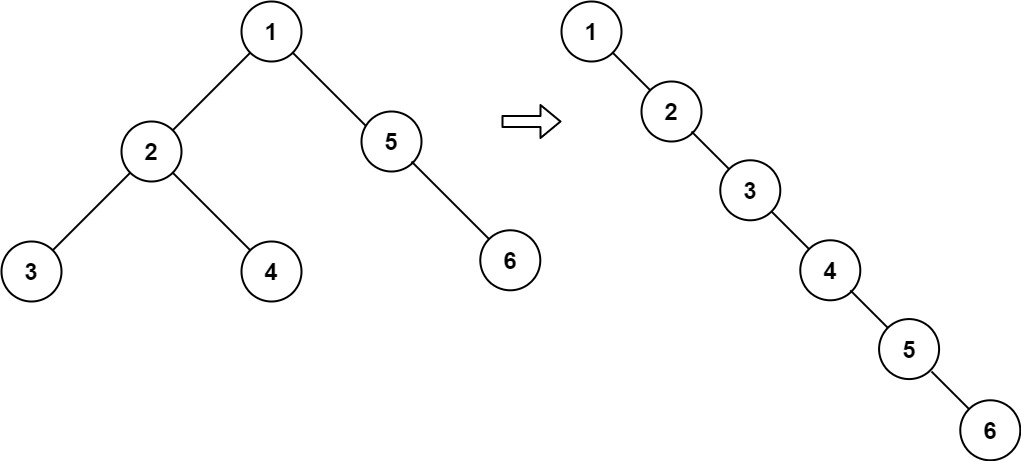
- 输入:root = [1,2,5,3,4,null,6]
- 输出:[1,null,2,null,3,null,4,null,5,null,6]
解:
前序遍历:中左右,若一边遍历一遍构造新链表,则会破环树导致失败。
后序遍历:右左中,顺序与前序相反,且遍历从叶子节点开始,可以一边遍历一边拆解
class Solution:
head=None
def flatten(self, root: Optional[TreeNode]) -> None:
"""
Do not return anything, modify root in-place instead.
"""
if not root:
return
self.flatten(root.right)
self.flatten(root.left)
root.left=None
root.right=self.head
self.head=root47.从前序与中序遍历序列构造二叉树
给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。
示例 1:

- 输入: preorder = [3,9,20,15,7], inorder = [9,3,15,20,7]
- 输出: [3,9,20,null,null,15,7]
解:
前序: 中左右
中(xxxxxxxxx左)(xxxxxxxxx右)
中序:左中右
(xxxxxxxxx左)中(xxxxxxxxx右)
在中序序列找到前序[0]的index,得到左子树长度,根据长度划分为左中右三部分,左和右分别递归,中构造树节点,左右子树分别指向递归结果
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
if not preorder:
return None
left_size =inorder.index(preorder[0])
left=self.buildTree(preorder[1:1+left_size],inorder[:left_size])
right=self.buildTree(preorder[1+left_size:],inorder[left_size+1:])
return TreeNode(preorder[0],left,right)48.路径总和 III
给定一个二叉树的根节点 root ,和一个整数 targetSum ,求该二叉树里节点值之和等于 targetSum 的 路径 的数目。
路径 不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
示例 1:
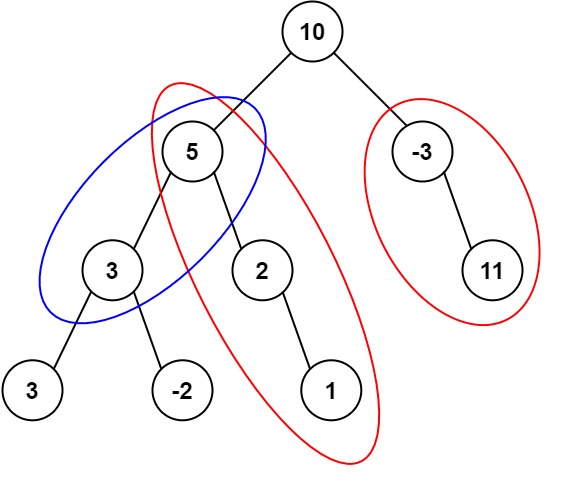
- 输入:root = [10,5,-3,3,2,null,11,3,-2,null,1], targetSum = 8
- 输出:3
- 解释:和等于 8 的路径有 3 条,如图所示。
解:
中序遍历,并用字典记录路径上的所有和的个数,当s-target在pre记录中可查到时,ans加上这个值,遍历到终点回溯时将pre中的s记录减1
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> int:
ans = 0
pre = defaultdict(int)
pre[0] = 1
def dfs(node: Optional[TreeNode],s:int) -> None:
nonlocal ans
# 当前节点为空则返回
if not node:
return
s+=node.val
ans +=pre[s-targetSum]
pre[s]+=1
dfs(node.left,s)
dfs(node.right,s)
pre[s]-=1
dfs(root,0)
return ans49.二叉树的最近公共祖先
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
百度百科中最近公共祖先的定义为:“对于有根树 T 的两个节点 p、q,最近公共祖先表示为一个节点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
示例 1:

- 输入:root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1
- 输出:3
- 解释:节点
5和节点1的最近公共祖先是节点3 。
解:
前序遍历,中左右,root为目标节点即返回,不再向下递归。
class Solution:
def lowestCommonAncestor(self, root: 'TreeNode', p: 'TreeNode', q: 'TreeNode') -> 'TreeNode':
if root in (None, p, q): # 找到 p 或 q 就不往下递归了,原因见上面答疑
return root
left = self.lowestCommonAncestor(root.left, p, q)
right = self.lowestCommonAncestor(root.right, p, q)
if left and right: # 左右都找到
return root # 当前节点是最近公共祖先
# 如果只有左子树找到,就返回左子树的返回值
# 如果只有右子树找到,就返回右子树的返回值
# 如果左右子树都没有找到,就返回 None(注意此时 right = None)
return left or right50.二叉树中的最大路径和
二叉树中的 路径 被定义为一条节点序列,序列中每对相邻节点之间都存在一条边。同一个节点在一条路径序列中 至多出现一次 。该路径 至少包含一个 节点,且不一定经过根节点。
路径和 是路径中各节点值的总和。
给你一个二叉树的根节点 root ,返回其 最大路径和 。
示例 1:
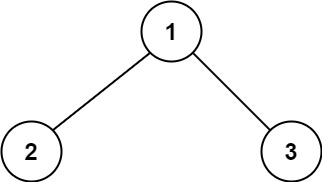
- 输入:root = [1,2,3]
- 输出:6
- 解释:最优路径是 2 -> 1 -> 3 ,路径和为 2 + 1 + 3 = 6
解:
后续遍历递归,某节点的最大值为其左节点递归结果加上右节点递归结果,某分支结果小于0则直接舍去,取0
class Solution:
def maxPathSum(self, root: Optional[TreeNode]) -> int:
ans = -inf
def dfs(node: Optional[TreeNode]) -> int:
if node is None:
return 0 # 没有节点,和为 0
l_val = dfs(node.left) # 左子树最大链和
r_val = dfs(node.right) # 右子树最大链和
nonlocal ans
ans = max(ans, l_val + r_val + node.val) # 两条链拼成路径
return max(max(l_val, r_val) + node.val, 0) # 当前子树最大链和(注意这里和 0 取最大值了)
dfs(root)
return ans51.岛屿数量
给你一个由 '1'(陆地)和 '0'(水)组成的的二维网格,请你计算网格中岛屿的数量。
岛屿总是被水包围,并且每座岛屿只能由水平方向和/或竖直方向上相邻的陆地连接形成。
此外,你可以假设该网格的四条边均被水包围。
示例 1:
输入:grid = [
['1','1','1','1','0'],
['1','1','0','1','0'],
['1','1','0','0','0'],
['0','0','0','0','0']
]
输出:1
解:
通过深度优先搜索将相连的1全部置为2(递归),遍历数组寻找1,找到一个1后启动dfs,并岛屿计数加1
class Solution:
def numIslands(self, grid: List[List[str]]) -> int:
row_n=len(grid)
col_n=len(grid[0])
def dfs(row:int,col:int)->None:
if row <0 or row>=row_n or col<0 or col>=col_n or grid[row][col]!='1' :
return
grid[row][col]='2'
dfs(row,col-1)
dfs(row,col+1)
dfs(row-1,col)
dfs(row+1,col)
ans=0
for row,line in enumerate(grid):
for col,num in enumerate(line):
if num =='1':
dfs(row,col)
ans+=1
return ans52.腐烂的橘子
在给定的 m x n 网格 grid 中,每个单元格可以有以下三个值之一:
- 值
0代表空单元格; - 值
1代表新鲜橘子; - 值
2代表腐烂的橘子。
每分钟,腐烂的橘子 周围 4 个方向上相邻 的新鲜橘子都会腐烂。
返回 直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1 。
示例 1:
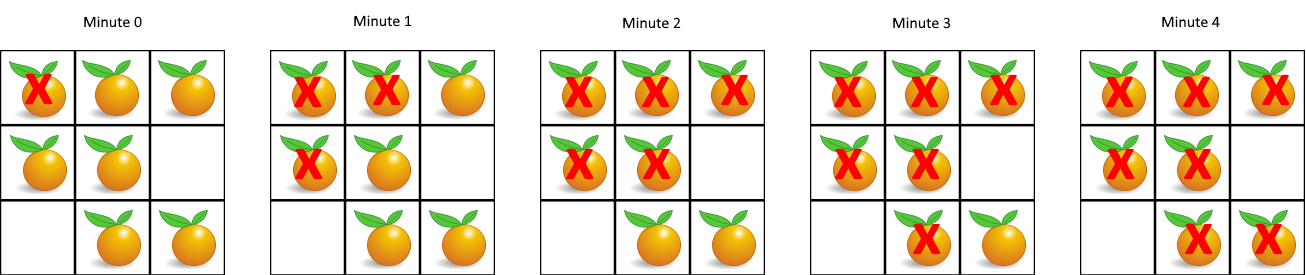
- 输入:grid = [[2,1,1],[1,1,0],[0,1,1]]
- 输出:4
解:
记录腐烂水果的坐标,存入数组,记录新鲜水果的个数
遍历腐烂水果的坐标,判断其四个方位的水果是否新鲜,是则将其加入腐烂水果的坐标,旧坐标清空,新鲜水果计数减1,时间计数每轮加1
当腐烂水果坐标数组为空或新鲜水果数为0,循环结束
class Solution:
def orangesRotting(self, grid: List[List[int]]) -> int:
r=[]
f=0
ans=0
m,n=len(grid),len(grid[0])
for row,line in enumerate(grid):
for col,num in enumerate(line):
if num==2:
r.append((row,col))
elif num==1:
f+=1
while r and f:
tmp=r
ans+=1
r=[]
for row,col in tmp:
for row_,col_ in (row-1,col),(row+1,col),(row,col-1),(row,col+1):
if 0<=row_<m and 0<=col_<n and grid[row_][col_]==1:
f-=1
grid[row_][col_]=2
r.append((row_,col_))
return -1 if f else ans53.课程表
你这个学期必须选修 numCourses 门课程,记为 0 到 numCourses - 1 。
在选修某些课程之前需要一些先修课程。 先修课程按数组 prerequisites 给出,其中 prerequisites[i] = [ai, bi] ,表示如果要学习课程 ai 则 必须 先学习课程 bi 。
- 例如,先修课程对
[0, 1]表示:想要学习课程0,你需要先完成课程1。
请你判断是否可能完成所有课程的学习?如果可以,返回 true ;否则,返回 false 。
示例 1:
- 输入:numCourses = 2, prerequisites = [[1,0]]
- 输出:true
- 解释:总共有 2 门课程。学习课程 1 之前,你需要完成课程 0 。这是可能的。
解:
g=[[] for _ in range(numCourses)初始化空邻接表,g[待修课程].append(前置课程)
依次遍历所有课程,递归遍历其邻接列表,dfs遍历到标记
class Solution:
def canFinish(self, numCourses: int, prerequisites: List[List[int]]) -> bool:
g = [[] for _ in range(numCourses)]
for a, b in prerequisites:
g[b].append(a)
colors = [0] * numCourses
# 返回 True 表示找到了环
def dfs(x: int) -> bool:
colors[x] = 1 # x 正在访问中
for y in g[x]:
# 情况一:colors[y] == 1,表示发生循环依赖,找到了环
# 情况二:colors[y] == 0,没有访问过 y,继续递归 y 获取信息
# 情况三:colors[y] == 2,重复访问 y 只会重蹈覆辙,和之前一样无法找到环,跳过
if colors[y] == 1 or colors[y] == 0 and dfs(y):
return True # 找到了环
colors[x] = 2 # x 完全访问完毕,从 x 出发无法找到环
return False # 没有找到环
for i, c in enumerate(colors):
if c == 0 and dfs(i):
return False # 有环
return True # 没有环54.全排列
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
示例 1:
- 输入:nums = [1,2,3]
- 输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
解:
定义一个标记数组,已加入结果的标记为True,递归遍历,直到计数n等于列表长,加入结果并回溯
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
l=len(nums)
ans=[]
flg_nums=[False]*l
temp=[]
def dfs(n:int)->None:
if n==l:
ans.append(temp[:])
return
for index,flag in enumerate(flg_nums):
if not flag:
flg_nums[index]=True
temp.append(nums[index])
dfs(n+1)
flg_nums[index]=False
temp.pop()
dfs(0)
return ans55.子集
给你一个整数数组 nums ,数组中的元素 互不相同 。返回该数组所有可能的子集(幂集)。
解集 不能 包含重复的子集。你可以按 任意顺序 返回解集。
示例 1:
- 输入:nums = [1,2,3]
- 输出:[[],[1],[2],[1,2],[3],[1,3],[2,3],[1,2,3]]
解:
递归,每次dfs时选择取这个数或不取这个数,取数后回溯时注意复原中间结果
class Solution:
def subsets(self, nums: List[int]) -> List[List[int]]:
n=len(nums)
ans=[]
path=[]
def dfs(i:int)->None:
if i==n:
ans.append(path[:])
return
dfs(i+1)
path.append(nums[i])
dfs(i+1)
path.pop()
dfs(0)
return ans56.搜索插入位置
给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
请必须使用时间复杂度为 O(log n) 的算法。
示例 1:
- 输入: nums = [1,3,5,6], target = 5
- 输出: 2
解:
典型二分查找
class Solution:
def searchInsert(self, nums: List[int], target: int) -> int:
l,r=0,len(nums)-1
while l<=r:
mid =(l+r)//2
if nums[mid]<target:
l=mid+1
else:
r=mid-1
return l57. 搜索二维矩阵
给你一个满足下述两条属性的 m x n 整数矩阵:
- 每行中的整数从左到右按非严格递增顺序排列。
- 每行的第一个整数大于前一行的最后一个整数。
给你一个整数 target ,如果 target 在矩阵中,返回 true ;否则,返回 false 。
示例 1:

- 输入:matrix = [[1,3,5,7],[10,11,16,20],[23,30,34,60]], target = 3
- 输出:true
解:
将矩阵当成m*n长度的列表,同样进行二分查找,中间多一步坐标解析
class Solution:
def searchMatrix(self, matrix: List[List[int]], target: int) -> bool:
row,col =len(matrix),len(matrix[0])
l,r=0,row*col-1
while l<=r:
mid =(l+r)//2
mid_row=mid//col
mid_col=mid%col
if matrix[mid_row][mid_col]<target:
l=mid+1
elif matrix[mid_row][mid_col]>target:
r=mid-1
else :
return True
return False57.在排序数组中查找元素的第一个和最后一个位置
给你一个按照非递减顺序排列的整数数组 nums,和一个目标值 target。请你找出给定目标值在数组中的开始位置和结束位置。
如果数组中不存在目标值 target,返回 [-1, -1]。
你必须设计并实现时间复杂度为 O(log n) 的算法解决此问题。
示例 1:
- 输入:nums = [
5,7,7,8,8,10], target = 8 - 输出:[3,4]
解:
二分查找,当nums[mid]<target时,l=mid+1,其他情况下right左移,虽然right会移到小于target的数上,但是当l==r时,这一轮判断会让l右移,因此l会指向第一个target。在检索target+1的位置,找到后减一即为target最后一位位置。
class Solution:
def erfen(self, nums: List[int], target: int)->int:
l,r=0,len(nums)-1
while l<=r:
mid =(l+r)//2
if nums[mid]<target:
l=mid+1
else:
r=mid-1
return l
def searchRange(self, nums: List[int], target: int) -> List[int]:
left=self.erfen(nums,target)
//注意先判断left是否越界,再判断nums[left]值对不对
if left==len(nums) or nums[left]!=target :
return[-1,-1]
right=self.erfen(nums,target+1)-1
return [left,right]58.最小栈
设计一个支持 push ,pop ,top 操作,并能在常数时间内检索到最小元素的栈。
实现 MinStack 类:
MinStack()初始化堆栈对象。void push(int val)将元素val推入堆栈。void pop()删除堆栈顶部的元素。int top()获取堆栈顶部的元素。int getMin()获取堆栈中的最小元素。
示例 1:
输入:
["MinStack","push","push","push","getMin","pop","top","getMin"]
[[],[-2],[0],[-3],[],[],[],[]]
输出:[null,null,null,null,-3,null,0,-2]
解释:
MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
minStack.getMin(); --> 返回 -3.
minStack.pop();
minStack.top(); --> 返回 0.
minStack.getMin(); --> 返回 -2.
解:
正常栈逻辑,并额外存储前缀最小值
class MinStack:
def __init__(self):
self.st=[(0,inf)]
def push(self, val: int) -> None:
self.st.append((val,min(self.st[-1][1],val)))
def pop(self) -> None:
self.st.pop()
def top(self) -> int:
return self.st[-1][0]
def getMin(self) -> int:
return self.st[-1][1]59.有效的括号
给定一个只包括 '(',')','{','}','[',']' 的字符串 s ,判断字符串是否有效。
有效字符串需满足:
- 左括号必须用相同类型的右括号闭合。
- 左括号必须以正确的顺序闭合。
- 每个右括号都有一个对应的相同类型的左括号。
示例 1:
输入:s = "()"
输出:true
解:
检测到右括号时判断pop元素是否为对应左括号,对则继续,不对则返回fa'l'se
class Solution:
def isValid(self, s: str) -> bool:
if len(s)%2:
return False
mp={')':'(',']':'[','}':'{'}
d=[]
for i in s:
if i not in mp:
d.append(i)
elif not d or d.pop()!=mp[i]:
return False
return not d60.买卖股票的最佳时机
给定一个数组 prices ,它的第 i 个元素 prices[i] 表示一支给定股票第 i 天的价格。
你只能选择 某一天 买入这只股票,并选择在 未来的某一个不同的日子 卖出该股票。设计一个算法来计算你所能获取的最大利润。
返回你可以从这笔交易中获取的最大利润。如果你不能获取任何利润,返回 0 。
示例 1:
- 输入:[7,1,5,3,6,4]
- 输出:5
- 解释:在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。
- 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格;同时,你不能在买入前卖出股票。
解:
存下当前最大利润与前缀最小值,遍历新价格减去前缀最小值,得到新利润并对比
class Solution:
def maxProfit(self, prices: List[int]) -> int:
ans=0
min_num=prices[0]
for i in prices:
ans=max(ans,i-min_num)
min_num=min(min_num,i)
return ans61.跳跃游戏
给你一个非负整数数组 nums ,你最初位于数组的 第一个下标 。数组中的每个元素代表你在该位置可以跳跃的最大长度。
判断你是否能够到达最后一个下标,如果可以,返回 true ;否则,返回 false 。
示例 1:
- 输入:nums = [2,3,1,1,4]
- 输出:true
- 解释:可以先跳 1 步,从下标 0 到达下标 1, 然后再从下标 1 跳 3 步到达最后一个下标。
解:
逐步扩张可到达区域,若i超出区域,返回False
class Solution:
def canJump(self, nums: List[int]) -> bool:
mx = 0
for i, jump in enumerate(nums):
if i > mx: # 无法到达 i
return False
mx = max(mx, i + jump) # 从 i 最右可以跳到 i+jump
return True62.爬楼梯
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
示例 1:
- 输入:n = 2
- 输出:2
- 解释:有两种方法可以爬到楼顶。
- 1. 1 阶 + 1 阶
- 2. 2 阶
解:
有两种走法,走一步或者走两步,所以dp[i]=dp[i-1]+dp[i-1]
class Solution:
def climbStairs(self, n: int) -> int:
dp=[0]*(n+1)
dp[0]=1
dp[1]=1
for i in range(2,n+1):
dp[i]=dp[i-1]+dp[i-2]
return dp[n]63.排序数组(手撕快排)
给你一个整数数组 nums,请你将该数组升序排列。
你必须在 不使用任何内置函数 的情况下解决问题,时间复杂度为 O(nlog(n)),并且空间复杂度尽可能小。
示例 1:
- 输入:nums = [5,2,3,1]
- 输出:[1,2,3,5]
- 解释:数组排序后,某些数字的位置没有改变(例如,2 和 3),而其他数字的位置发生了改变(例如,1 和 5)。
解:
定义一个partition子函数,随机在此区间内挑一个数pivot与left位置的数交换,再从左右向中间遍历,小于pivot的左置,大于pivot的右置,最后r会指向最后一个小于pivot的数,将pivot与此数交换位置,返回pivot最终的位置
定义快排递归函数quicksort,当数组有序时直接返回,无序时执行partition函数,返回分界线i,因为左边全是小于pivot的,右边全是大于pivot的,因此pivot的位置是固定的。再用quicksort分别递归(left,i-1)和(i+1,right),将未确定部分确定
class Solution:
def partition(self,nums: List[int],Left:int,right:int )->int:
i=randint(Left,right)
pivot=nums[i]
nums[i],nums[Left]=nums[Left],nums[i]
l,r=Left+1,right
while True:
while l<=r and nums[l]<pivot:
l+=1
while l<=r and nums[r]>pivot:
r-=1
if l>=r:
break
nums[l],nums[r]=nums[r],nums[l]
l+=1
r-=1
nums[Left],nums[r] =nums[r],nums[Left]
return r
def sortArray(self, nums: List[int]) -> List[int]:
def quicksort(Left:int ,right:int)->None:
ordered=True
for i in range(Left,right):
if nums[i]>nums[i+1]:
ordered=False
break
if ordered:
return
i=self.partition(nums,Left,right)
quicksort(Left,i-1)
quicksort(i+1,right)
quicksort(0,len(nums)-1)
return nums64.实现 Trie (前缀树)
Trie(发音类似 "try")或者说 前缀树 是一种树形数据结构,用于高效地存储和检索字符串数据集中的键。这一数据结构有相当多的应用情景,例如自动补全和拼写检查。
请你实现 Trie 类:
Trie()初始化前缀树对象。void insert(String word)向前缀树中插入字符串word。boolean search(String word)如果字符串word在前缀树中,返回true(即,在检索之前已经插入);否则,返回false。boolean startsWith(String prefix)如果之前已经插入的字符串word的前缀之一为prefix,返回true;否则,返回false。
示例:
- 输入
- ["Trie", "insert", "search", "search", "startsWith", "insert", "search"]
- [[], ["apple"], ["apple"], ["app"], ["app"], ["app"], ["app"]]
- 输出[null, null, true, false, true, null, true]
解释
Trie trie = new Trie();
trie.insert("apple");
trie.search("apple"); // 返回 True
trie.search("app"); // 返回
False trie.startsWith("app"); // 返回 True
trie.insert("app");
trie.search("app"); // 返回 True
解:
定义树节点包含 son={}和结束标志end
构造树时在节点的son中查找是否有此元素c,没有则加入此元素cur.son[c],并移动cur至cur.son[c],存在则直接移动至cur.son[c]
class Node:
def __init__(self):
self.son={}
self.end=False
class Trie:
def __init__(self):
self.root=Node()
def insert(self, word: str) -> None:
cur=self.root
for c in word:
if c not in cur.son:
cur.son[c]=Node()
cur=cur.son[c]
cur.end=True
def find(self, word: str)->int:
cur=self.root
for c in word:
if c in cur.son:
cur=cur.son[c]
else:
return 0
return 2 if cur.end==True else 1
def search(self, word: str) -> bool:
if self.find(word)==2:
return True
else:
return False
def startsWith(self, prefix: str) -> bool:
if self.find(prefix):
return True
else :
return False
Comments NOTHING